

-
Data storage systems are the most attacked IT assets
Although cloud environments offer stringent security measures to keep your data safe, sophisticated cyberattacks that target the cloud’s shared responsibility model are on the rise.
-
4 key disaster recovery strategies for your cloud infrastructure
For customers who leverage cloud workloads for their data, our partners at AWS offer key disaster recovery strategies aimed at improving their data resiliency.
-
Backup and restore
In this strategy, your AWS-hosted data and configurations are regularly backed up and stored in a reliable location, which usually means a different AWS region. The recovery is done by simply restoring from these backups when a disaster occurs.
-
Pilot light
The pilot light approach keeps a live copy of the core components of your AWS infrastructure in a different AWS region, while supplementary components are kept inactive until a disaster occurs.
-
Warm standby
Warm standby involves a scaled-down version of your production environment running continuously. When a disaster occurs, it is rapidly scaled to full production capacity and takes the place of any failed resources.
-
Multisite active/active
This strategy involves running identical full-scale environments in multiple locations. Each site is fully capable of handling the entire workload, ensuring that if one site fails, others can take over instantly without any downtime.
-
Start your disaster recovery journey with AWS and CDW
At CDW, we are an AWS Esteemed Consulting Partner with expertise and experience in designing, implementing and managing backup and disaster recovery. We accompany you in your disaster recovery journey to meet objectives unique to your organization.
4 Disaster Recovery Strategies to Make You Resilient to Evolving Cyberthreats
In this blog, we discuss how IT decision-makers can use cloud disaster recovery measures to protect their infrastructure. We delve into the cyberthreat landscape and provide four key strategies for better disaster recovery from our partners at AWS.


In a cyberattack scenario, your data is the hardest IT asset to recover. Especially if it is compromised, encrypted or destroyed in the attack.
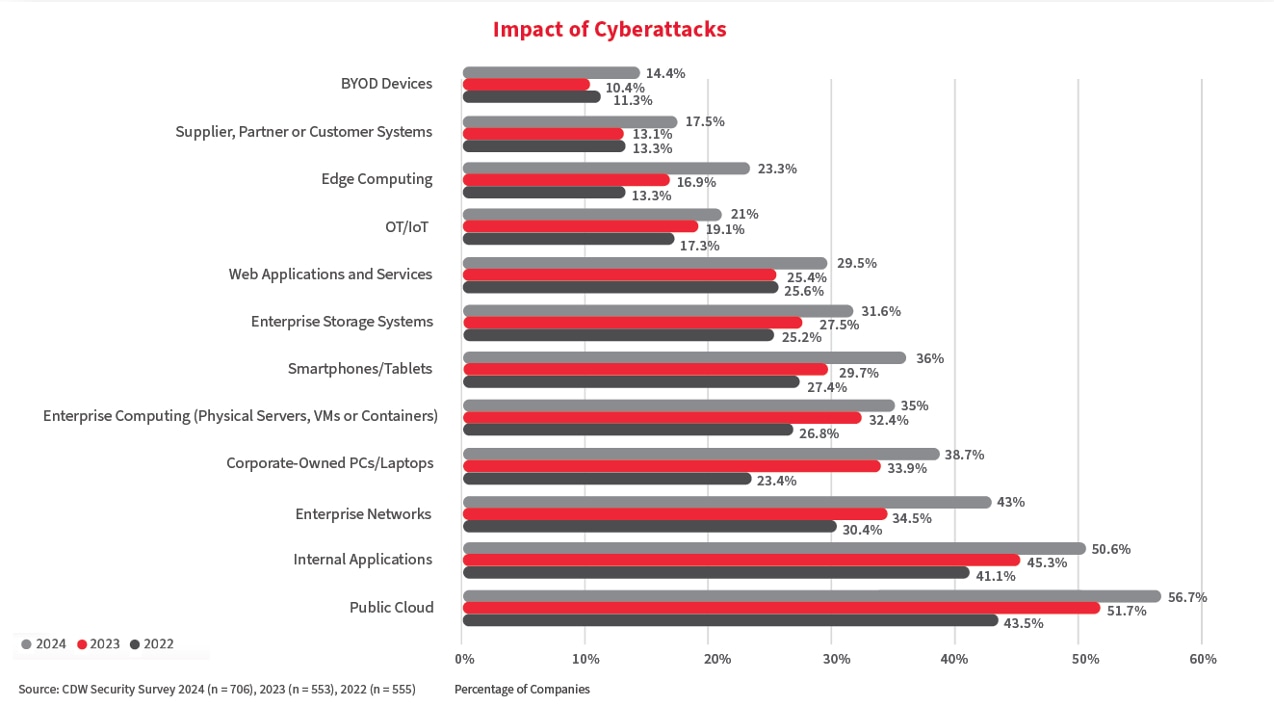
Knowing this well, cyberattackers have begun targeting data storage systems across Canadian organizations with greater sophistication. Our 2024 Canadian Cybersecurity Study found that public cloud, which is used for data-intensive workloads, had the largest share of such attacks.
Given this scenario, standard data backup and recovery mechanisms may not offer full protection for organizations with cloud investments. They need a well-architected disaster recovery strategy that can defend against cyberthreats and build data resiliency.
In this blog, we discuss how IT decision-makers can utilize cloud disaster recovery measures to protect their infrastructure. We delve into the evolving cyberthreat landscape and provide four key strategies for better disaster recovery from our partners at AWS.
Data storage systems are the most attacked IT assets
Our 2024 Canadian Cybersecurity Study observed the impact of cyberattacks across the various assets contained in a typical IT environment. The study found that public cloud was the most impacted IT asset, with 56.7 percent of companies reporting cyberattacks in 2024, up from 43.5 percent in 2022.
At the same time, the amount of enterprise storage systems impacted also jumped from 25.2 percent to 31.6 percent between 2022 and 2024.
Although cloud environments offer stringent security measures to keep your data safe, sophisticated cyberattacks that target the cloud’s shared responsibility model are on the rise. Rather than breaching the cloud provider’s security, attackers may try to steal your administrator credentials or execute ransomware attacks that can put your internal defences at risk.
These trends signal that more organizations may face increased cyberattacks to their storage systems in the future, making it critical to have a robust data backup strategy in place.
Disaster recovery and backups can get complex
A disaster recovery strategy isn’t limited to creating a safe copy of your data. It comes with a list of recovery objectives and SLAs to ensure your data stays resilient, such as:
- Recover the right amount of data to the right point in time
- Recovery speed should meet business requirements
- Backed up data should be protected from damage and corruption
- Backups should exist in an air-gapped location
- Right access and authorization should be configured
- Infrastructure must reinstate to a given operational status on recovery
If your data exists in a combination of cloud and on-premises resources, meeting backup and recovery objectives can get even more challenging. IT teams often need to craft a careful strategy that can align backup logistics such as disparate environments, storage costs, third-party risk and technical overheads.
4 key disaster recovery strategies for your cloud assets
For customers who leverage cloud workloads for their data, our partners at AWS offer key disaster recovery strategies aimed at improving their data resiliency.
These strategies allow cloud practitioners to seamlessly plan how to configure AWS services, allocate resources and automate backups within their system architecture. Each strategy is designed to serve a different disaster recovery scenario based on what assets they want to back up and how quickly they want to recover them.
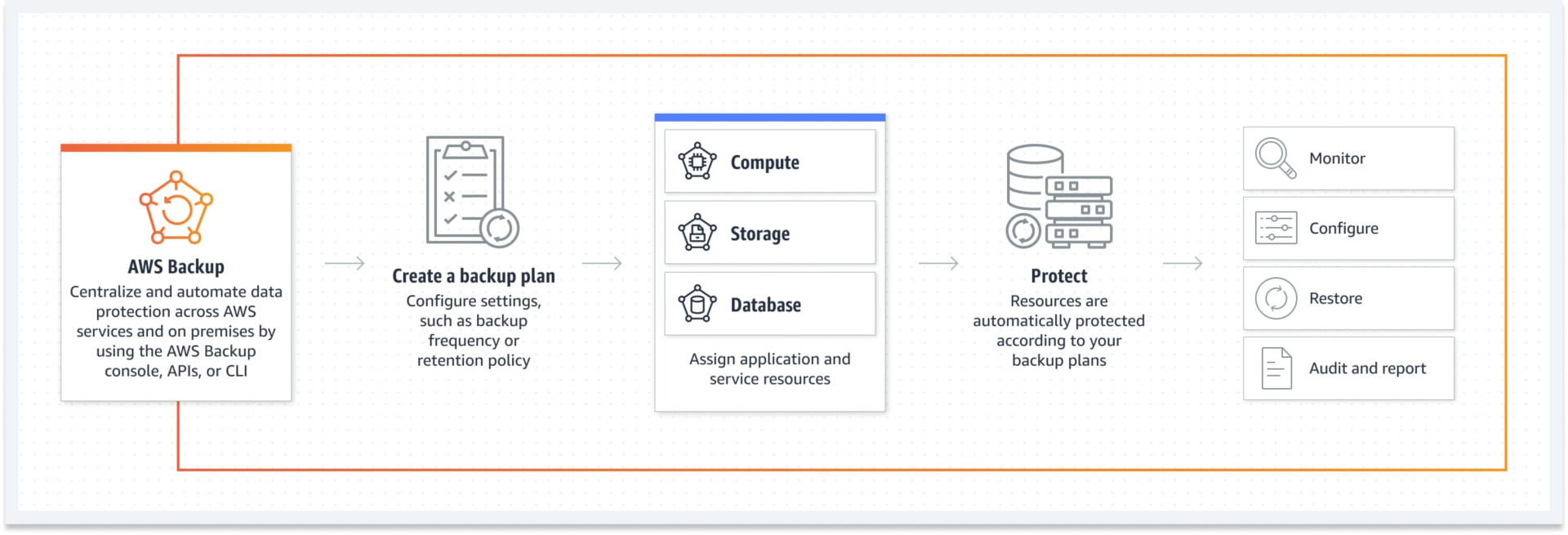
1. Backup and restore
In this strategy, your AWS-hosted data and configurations are regularly backed up and stored in a reliable location, which usually means a different AWS region. The recovery is done by simply restoring from these backups when a disaster occurs.
The strategy provides a mechanism for backing up your EBS volumes, EC2 instances, RDS databases and EFS snapshots among other resources using AWS Backup service.
How to architect
The architecture involves the AWS Backup service, AWS S3 and an additional AWS region for replication. The Backup service offers a centralized control plane for configuring backups across AWS resources. Practitioners can build plans and policies for continuous backups for their most critical workloads.
Data is backed up to AWS services like S3 or S3 Glacier that are replicated to the new region. When disaster strikes, these backups are restored and systems are reprovisioned from the separate region.
Note: While the service offers backup automation, the recovery must be automated using the additional API calls that can be configured using AWS Lambda and AWS SNS.
Covered scenarios
This solution is well-suited for non-critical applications with lower uptime needs, like development environments, file sharing platforms or email services, where occasional downtime is acceptable. Recovery time objective (RTO) and recovery point objective (RPO) tend to be longer, depending on the backup intervals and the complexity of the restore process.
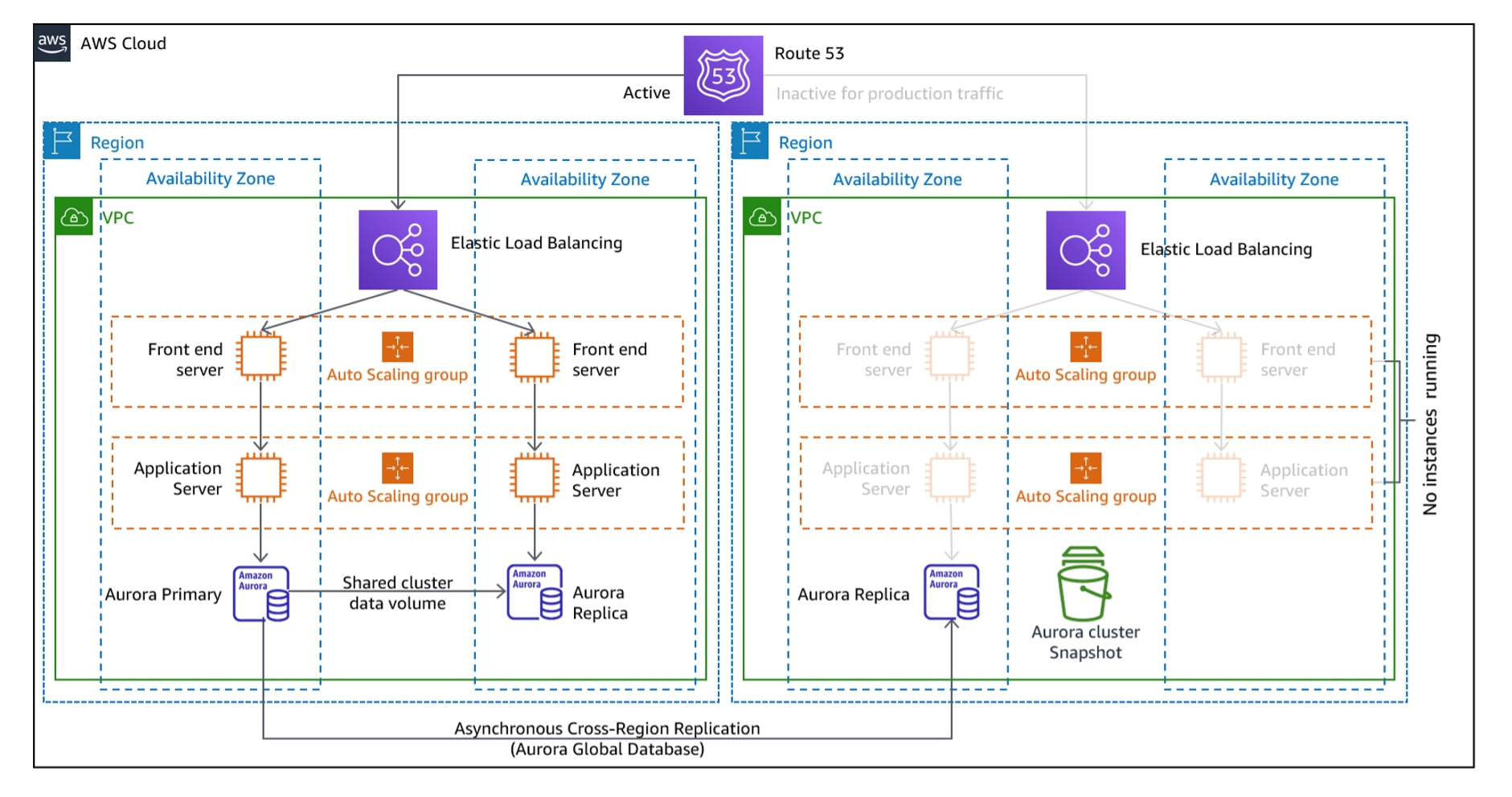
2. Pilot light
The pilot light approach keeps a live copy of the core components of your AWS infrastructure in a different AWS region, while supplementary components are kept inactive until a disaster occurs.
Imagine having a duplicate but partially working version of your cloud architecture always ready in a different region. You can switch it completely on when needed, and your data is actively replicated to the backup region.
How to architect
The architecture hinges on achieving data replication and quicky scaling out inactive standby resources.
The cross-region data replication (between the main and the backup region) is achieved using:
- Amazon S3 Replication
- Amazon RDS read replicas
- Amazon Aurora global databases
- Amazon DynamoDB global tables
Whereas the dormant resources are spun to life at speed using AWS Auto Scaling and AWS Elastic Load Balancing.
Core services (like a database) are always running with minimal compute resources, such as an RDS instance. Application servers or other non-critical parts of the environment are inactive (e.g., in stopped EC2 instances). The strategy is designed in a way that when a disaster occurs, infrastructure can be rapidly scaled up to production levels.
Covered scenarios
Pilot light works well for systems that need quicker recovery than backup but don't require full-time redundancy, like eCommerce platforms where you need quick database access but can afford to scale the web or application tiers later. It allows for faster recovery compared to backup-only methods with a more manageable cost.
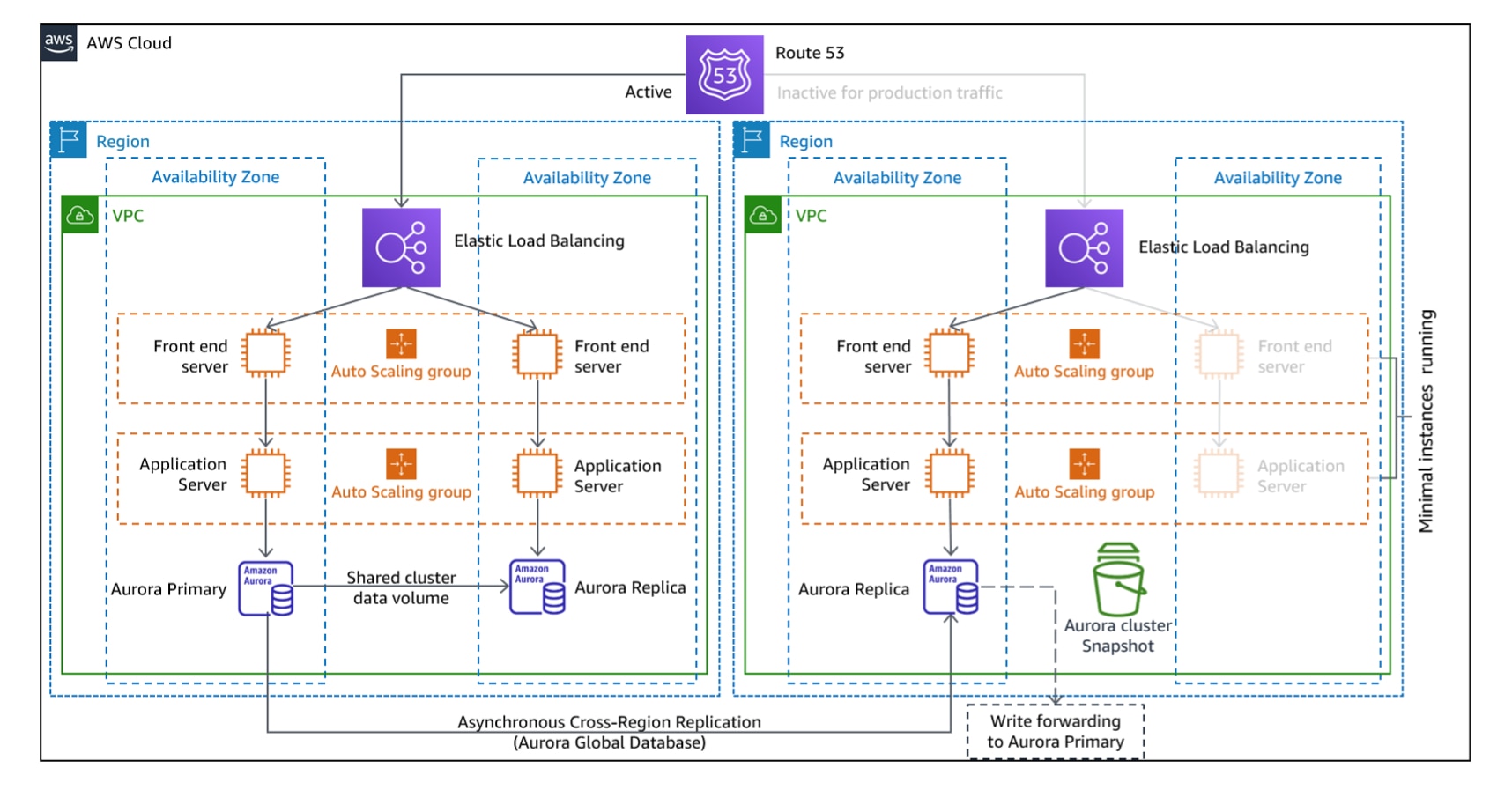
3. Warm standby
Warm standby involves a scaled-down version of your production environment running continuously. When a disaster occurs, it is rapidly scaled to full production capacity and takes the place of any failed resources.
This strategy, unlike pilot light, keeps the entire duplicate architecture in an operational state. Therefore, it can quickly spring into action when needed, offering a high-speed mechanism to recover infrastructure and prevent data loss.
How to architect
This strategy requires you to build a standby environment, which communicates with the main environment using the same replication services as the pilot light approach. The fastest way to create the copy environment is by using AWS CloudFormation templates with IaC. This can simplify the complex task of reprovisioning the services.
Upon disaster, the components of the copy environment can be scaled to meet production demands using AWS Elastic Beanstalk, Auto Scaling or scaling the instance types in AWS RDS.
- AWS EC2 (scaled-down): For running applications in standby.
- AWS RDS (smaller instance): For database operations.
- AWS Auto Scaling, Elastic Beanstalk: For scaling services up when needed.
- AWS Route 53: For DNS routing to the standby environment.
Covered scenarios
Suitable for critical applications where downtime needs to be minimized but not completely eliminated, such as SaaS applications where user availability is important but can afford brief disruptions. It offers lower RTO and RPO compared to pilot light as well as backup and restore strategies.
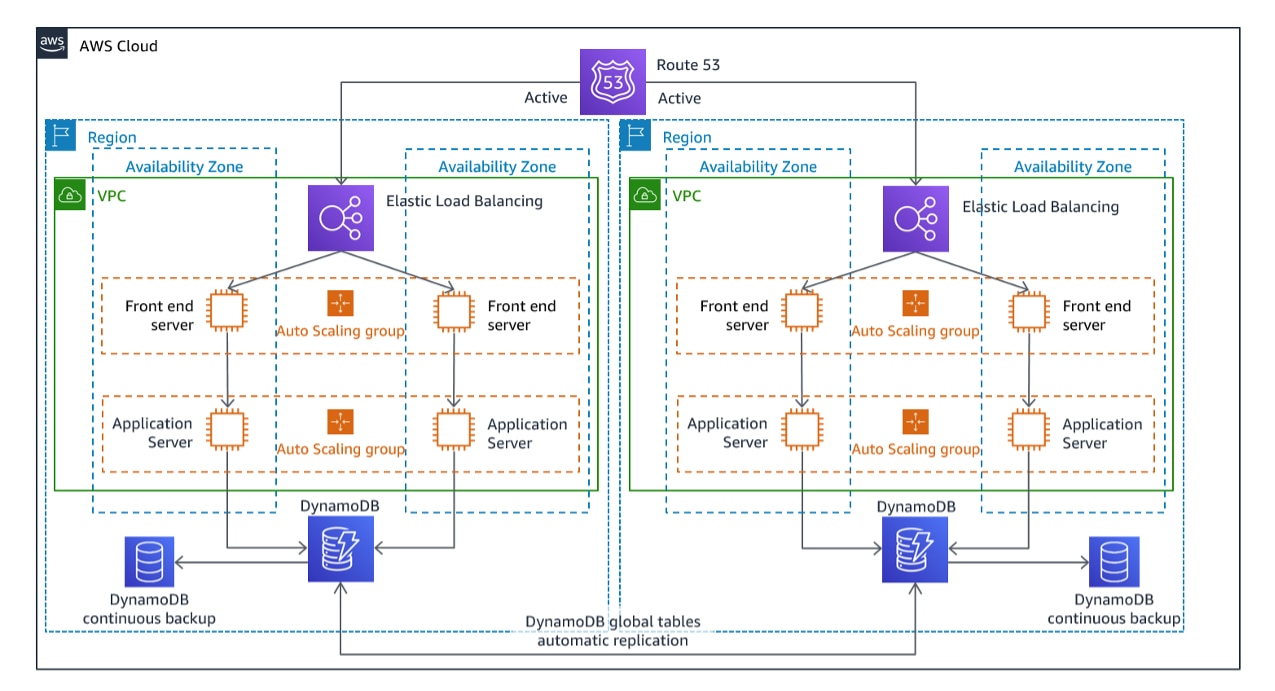
4. Multisite active/active
This strategy involves running identical full-scale environments in multiple locations (regions) that actively serve traffic. Each site is fully capable of handling the entire workload, ensuring that if one site fails, others can take over instantly without any downtime.
The second replica of the main environment actively serves user traffic and is like a real-time copy you can switch to at any time without having to wait. There is another version of the same strategy called hot standby passive/active, which also has a full-scale standby environment, but it’s not used for serving live traffic.
How to architect
The architecture for this strategy is the hardest to achieve due to multiple full-scale environments. Organizations can keep multiple regions active by first building infrastructure replicas using AWS CloudFormation for simplifying the recreation process.
- Services like AWS CloudFormation StackSets can help improve the management of multiple environments deployed across regions.
- AWS Global Accelerator can also be leveraged to control the percentage of traffic that each active site must handle. In combination with AWS Route 53, which manages DNS, the two sites can achieve seamless availability.
- Active instances run simultaneously across AWS regions.
- Services like Route 53 can manage traffic distribution and health checks to ensure that all sites are operating correctly.
- If one region fails, traffic is automatically routed to another.
Covered scenarios
This strategy is best suited for mission-critical applications where zero downtime is a requirement, such as banking, financial services and global eCommerce platforms. It provides the lowest RTO and RPO, ensuring high availability even in the event of regional failures.
Start your disaster recovery journey with AWS and CDW
Whether you’re planning to migrate your data workloads to the cloud or you already use AWS services, it’s important have a data resiliency plan for cyberincidents.
At CDW, we are an AWS Esteemed Consulting Partner with deep expertise and experience in designing, implementing and managing backup and disaster recovery solutions.
We accompany you in your disaster recovery journey to meet the objectives unique to your organization. Be it backup testing, data restoration or monitoring, we ensure that your data is always protected and accessible.
By partnering with CDW and AWS, you can help your organization:
- Reduce disaster recovery costs: Save significantly on backup and disaster recovery costs by using AWS’ pay-as-you-go cloud services coupled with CDW’s expert licensing.
- Meet your scalability needs: Easily scale your backup and disaster recovery resources up or down, depending on your data volume and frequency. Our AWS experts help you architect your cloud environment to ensure it stays scalable.
- Secure your backups: Protect your data from unauthorized access or modification by using AWS security features, managed by our data security experts.
- Accomplish your recovery objectives: Ensure all your data can be quickly recovered within your predefined RTOs and RPOs with our AWS service configuration support.
- Ensure compliance: Our AWS-certified solution architects advise customers based on the AWS Well Architected Framework (WAF), which makes sure their strategies are aligned with the best practices.
With two decades of experience in the Canadian market and a dedicated team of over 80 cloud solution architects nationwide, we are well-equipped to address your data resiliency requirements. Our assess, architect, implement and operate model ensures comprehensive management of your data protection and data resiliency needs.
Our disaster recovery solutions ensure rapid data recovery, scalable protection and expert guidance, making us one of the leading AWS partners in Canada, with end-to-end capabilities.